Summary
- Task: render a scene from novel poses given just a few photos.
- Neural Radiance Fields (NeRF) generate crisp renderings with 20-100 photos, but overfit with only a few.
- Problem: NeRF is only trained to render observed poses, leading to artifacts when few are available.
- Key insight: Scenes share high-level semantic properties across viewpoints, and pre-trained 2D visual encoders can extract these semantics. "An X is an X from any viewpoint."
- Our proposed DietNeRF supervises NeRF from arbitrary poses by ensuring renderings have consistent high-level semantics using the CLIP Vision Transformer.
- We generate plausible novel views given 1-8 views of a test scene.
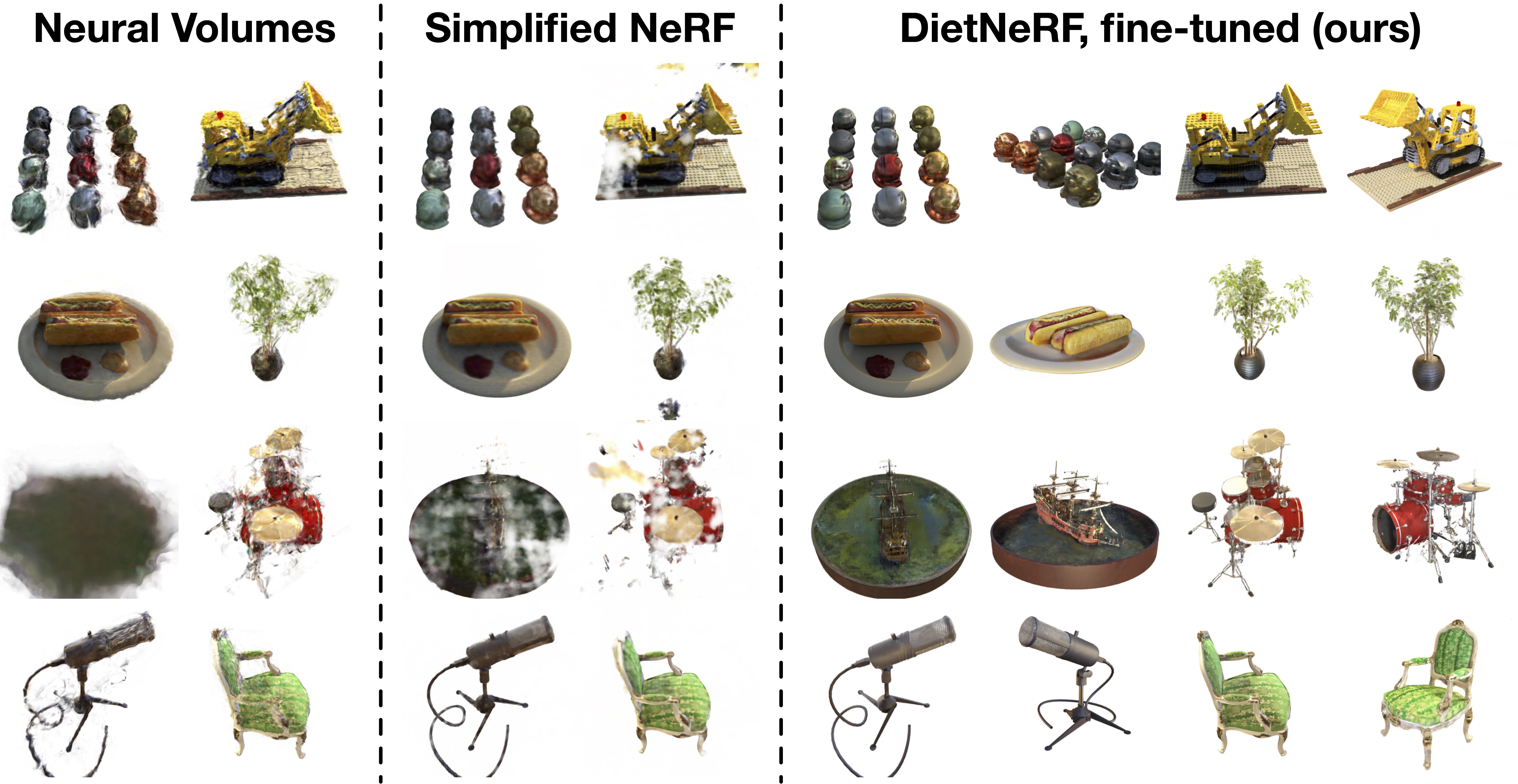
Novel views synthesized given 8 training images per object.

Our scene representation learns consistent high-level semantics.


 Semantic consistency improves perceptual quality from a single input view. Fine-tuning pixelNeRF with NeRF's MSE loss slightly improves a rendering of the input view, but does not remove most perceptual flaws like blurriness in novel views. Fine-tuning with both MSE and semantic consistency losses (DietPixelNeRF, bottom) improves sharpness of all views.
Semantic consistency improves perceptual quality from a single input view. Fine-tuning pixelNeRF with NeRF's MSE loss slightly improves a rendering of the input view, but does not remove most perceptual flaws like blurriness in novel views. Fine-tuning with both MSE and semantic consistency losses (DietPixelNeRF, bottom) improves sharpness of all views.